The majority of supply chains use siloed infrastructures, unverifiable paper records, and multi-party coordination to keep things moving operationally. But as regulatory requirements become more stringent and source traceability is no longer optional, such traditional infrastructure is not enough without the right IT consultancy support.
Blockchain fills this void by creating a common, tamper-evident layer of data that crosses suppliers, logistics providers, and regulatory authorities, yet does not replace current systems.
This piece examines how blockchain technology is being used in actual supply chain settings to enhance transparency where traditional systems lack.
Why Transparency in Supply Chains Is Now a Business Imperative
Governments are making it mandatory. Investors are requiring it. And operational risks are putting into the spotlight firms that lack it. A digital transformation consultant can help organizations navigate these pressures, as supply chain transparency has shifted from a long-term aspiration to an instant priority.
Here’s what’s pushing the change:
- Regulations worldwide are getting stricter quickly. The Corporate Sustainability Due Diligence Directive (CSDDD) from the European Union will require large companies to monitor and report on. Environmental and Human Rights harm within their supply chains. If a company is found to be in contravention of the legislation, the fine could be up to 5% of global turnover.
- Uncertainty about supply chains carries significant financial and reputational exposure.
- Today’s consumers want assurance. Consumers increasingly want proof of sourcing, whether it be “organic,” “conflict-free,” or “fair trade.” Greenwashing or broad assurances will no longer suffice.
Blockchain’s Role in Transparency of Supply Chains
Blockchain is designed to address a key weakness of modern supply chains, however. The reality of fragmented systems, vendors, and borders is a lack of end-to-end visibility.
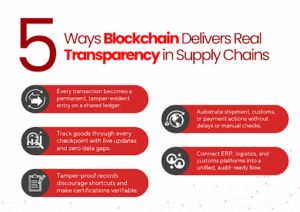
Here’s how it delivers that transparency in practice:
1. Immutable Records at Every Step
Each transaction, whether it’s raw material sourcing, shipping, or quality checks is logged as a permanent, timestamped entry.
No overwriting. No backdating. No selective visibility. Every party sees a shared version of the truth.
2. Real-Time Traceability
Blockchain lets you track goods as they move through each checkpoint, automatically updating status, location, and condition. This prevents data gaps between systems and reduces time spent chasing updates from vendors.
3. Supplier Accountability
When records are tamper-proof and accessible, suppliers are less likely to cut corners.
It’s no longer enough to claim ethical sourcing; blockchain makes it verifiable, down to the certificate or batch.
4. Smart Contracts for Rule Enforcement
Smart contracts automate enforcement:
- Was the shipment delivered on time?
- Did all customs documents clear?
If not, actions can trigger instantly, with no manual approvals or bottlenecks.
5. Interoperability Across Systems
Blockchain doesn’t replace your ERP or logistics software. Instead, it bridges them, connecting siloed systems into a single, auditable record that flows across the supply chain.
From tracking perishable foods to verifying diamond origins, blockchain has already proven its role in cleaning up opaque supply chains with results that traditional systems couldn’t match.
Real-World Applications of Blockchain in Supply Chain Tracking
Blockchain’s value in supply chains is being applied in industries where source verification, process integrity, and document traceability are non-negotiable. Below are real examples where blockchain has improved visibility at specific supply chain points.
1. Food Traceability — Walmart & IBM Food Trust
Challenge: Tracing food origins during safety recalls used to take Walmart 6–7 days, leaving a high contamination risk.
Application: By using IBM’s blockchain platform, Walmart reduced trace time to 2.2 seconds.
Outcome: This gives its food safety team near-instant visibility into the supply path, lot number, supplier, location, and temperature history, allowing faster recalls with less waste.
2. Ethical Sourcing — De Beers with Tracr
Challenge: Tracing diamonds back to ensure they are conflict-free has long relied on easily forged paper documents.
Application: De Beers applied Tracr, a blockchain network that follows each diamond’s journey from mine to consumer.
Outcome: Over 1.5 million diamonds are now digitally certified, with independently authenticated information for extraction, processing, and sale. This eliminates reliance on unverifiable supplier assurances.
3. Logistics Documentation — Maersk’s TradeLens
Challenge: Ocean freight involves multiple handoffs, ports, customs, and shippers, each using siloed paper-based documents, leading to fraud and delays.
Application: Maersk and IBM launched TradeLens, a blockchain platform connecting over 150 participants, including customs authorities and ports.
Outcome: Shipping paperwork is now in alignment among stakeholders near real-time, reducing delays and administrative charges in world trade.
All of these uses revolve around a specific point of supply chain breakdown, whether that’s trace time, trust in supplier data, or document synchronisation. Blockchain does not solve supply chains in general. It solves traceability when systems, as they exist, do not.
Business Benefits of Using Blockchain for Supply Chain Visibility
For teams responsible for procurement, logistics, compliance, and supplier management, blockchain doesn’t just offer transparency; it simplifies decision-making and reduces operational friction.
Here’s how:
- Speedier vendor verification: Bringing on a new supplier no longer requires weeks of documentation review. With blockchain, you have access to pre-validated certifications, transaction history, and sourcing paths, already logged and transferred.
- Live tracking in all tiers: No more waiting for updates from suppliers. You can follow product movement and status changes in real-time, from raw material to end delivery through every tier in your supply chain.
- Less paper documentation: Smart contracts eliminate unnecessary paper documentation on shipment, customs clearance, and vendor pay. Less time reconciling data between systems, fewer errors, and no conflicts.
- Better readiness for audits: When an audit comes or a regulation changes, you are not panicking. Your sourcing and shipping information is already time-stamped and locked in place, ready to be reviewed without cleanup.
- Lower dispute rates with suppliers: Blockchain prevents “who said what” situations. When every shipment, quality check, and approval is on-chain, accountability is the default.
- More consumer-facing claims: If sustainability is the core of your business, ethical sourcing, or authenticity of products, blockchain allows you to validate it. Instead of saying it, you show the data to support it.
Conclusion
Blockchain evolved from a buzzword to an underlying force for supply chain transparency. And yet to introduce it into actual production systems, where vendors, ports, and regulators still have disconnected workflows, is not a plug-and-play endeavor—this is where expert IT consultancy becomes essential.
That’s where SCS Tech comes in.
We support forward-thinking teams, SaaS providers, and integrators with custom-built blockchain modules that slot into existing logistics stacks, from traceability tools to permissioned ledgers that align with your partners’ tech environments.
FAQs
1. If blockchain data is public, how do companies protect sensitive supply chain details?
Most supply chain platforms use permissioned blockchains, where only authorized participants can access specific data layers. You control what’s visible to whom, while the integrity of the full ledger stays intact.
2. Can blockchain integrate with existing ERP or logistics software?
Yes. Blockchain doesn’t replace your systems; it connects them. Through APIs or middleware, it links ERP, WMS, or customs tools so they share verified records without duplicating infrastructure.
3. Is blockchain only useful for high-value or global supply chains?
Not at all. Even regional or mid-scale supply chains benefit, especially where supplier verification, product authentication, or audit readiness are essential. Blockchain works best where transparency gaps exist, not just where scale is massive.