
Utility companies encounter expensive equipment breakdowns that halt service and compromise safety. The greatest challenge is not repairing breakdowns, it’s predicting when they will occur.
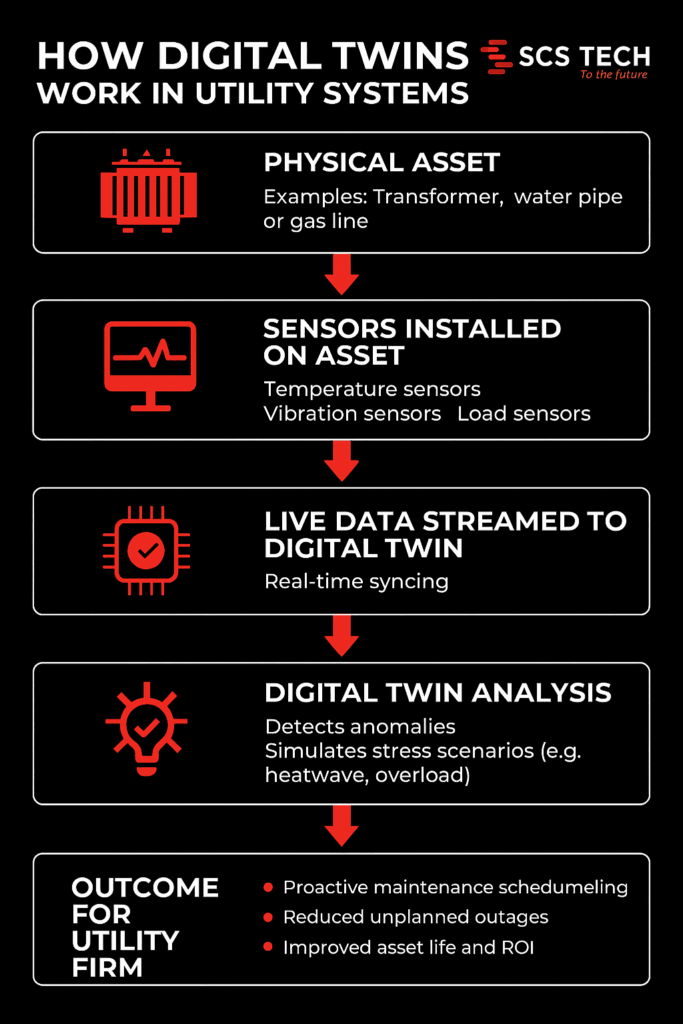
As part of a broader digital transformation strategy, digital twin tech produces virtual, real-time copies of physical assets, fueled by real-time sensor feeds such as temperature, vibration, and load. This dynamic model replicates asset health in real-time as it evolves.
Utilities identify early warning signs, model stress conditions, and predict failure horizons with digital twins. Maintenance becomes a proactive intervention in response to real conditions instead of reactive repairs.
The Digital Twin Technology Role in Failure Prediction
Utility firms run on tight margins for error. A single equipment failure — whether it’s in a substation, water main, or gas line — can trigger costly downtimes, safety risks, and public backlash. The problem isn’t just failure. It’s not knowing when something is about to fail.
Digital twin technology changes that.
At its core, a digital twin is a virtual replica of a physical asset or system. But this isn’t just a static model. It’s a dynamic, real-time environment fed by live data from the field.
- Sensors on physical assets capture metrics like:
- Temperature
- Pressure
- Vibration levels
- Load fluctuations
- That data streams into the digital twin, which updates in real time and mirrors the condition of the asset as it evolves.
This real-time reflection isn’t just about monitoring — it’s about prediction. With enough data history, utility firms can start to:
- Detect anomalies before alarms go off
- Simulate how an asset might respond under stress (like heatwaves or load spikes)
- Forecast the likely time to failure based on wear patterns
As a result, maintenance shifts from reactive to proactive. You’re no longer waiting for equipment to break or relying on calendar-based checkups. Instead:
- Assets are serviced based on real-time health
- Failures are anticipated — and often prevented
- Resources are allocated based on actual risk, not guesswork
In high-stakes systems where uptime matters, this shift isn’t just an upgrade — it’s a necessity.
Ways Digital Twin Technology is Helping Utility Firms Predict and Prevent Failures
1. Proactive Maintenance Through Real-Time Monitoring
In a typical utility setup, maintenance is either time-based (like changing oil every 6 months) or event-driven (something breaks, then it gets fixed). Neither approach adapts to how the asset is actually performing.
Digital twins allow firms to move to condition-based maintenance, using real-time data to catch failure indicators before anything breaks. This shift is a key component of any effective digital transformation strategy that utility firms implement to improve asset management.
Take this scenario:
- A substation transformer is fitted with sensors tracking internal oil temperature, moisture levels, and load current.
- The digital twin uses this live stream to detect subtle trends, like a slow rise in dissolved gas levels, which often points to early insulation breakdown.
- Based on this insight, engineers know the transformer doesn’t need immediate replacement, but it does need inspection within the next two weeks to prevent cascading failure.
That level of specificity is what sets digital twins apart from basic SCADA systems.
Other real-world examples include:
- Water utilities detecting flow inconsistencies that indicate pipe leakage, before it becomes visible or floods a zone.
- Wind turbine operators identifying torque fluctuations in gearboxes that predict mechanical fatigue.
Here’s what this proactive monitoring unlocks:
- Early detection of failure patterns — long before traditional alarms would trigger.
- Targeted interventions — send teams to fix assets showing real degradation, not just based on the calendar.
- Shorter repair windows — because issues are caught earlier and are less severe.
- Smarter budget use — fewer emergency repairs and lower asset replacement costs.
This isn’t just monitoring for the sake of data. It’s a way to read the early signals of failure — and act on them before the problem exists in the real world.
2. Enhanced Vegetation Management and Risk Mitigation
Vegetation encroachment is a leading cause of power outages and wildfire risks. Traditional inspection methods are often time-consuming and less precise. Digital twins, integrated with LiDAR and AI technologies, offer a more efficient solution. By creating detailed 3D models of utility networks and surrounding vegetation, utilities can predict growth patterns and identify high-risk areas.
This enables utility firms to:
- Map the exact proximity of vegetation to assets in real-time
- Predict growth patterns based on species type, local weather, and terrain
- Pinpoint high-risk zones before branches become threats or trigger regulatory violations
Let’s take a real-world example:
Southern California Edison used Neara’s digital twin platform to overhaul its vegetation management.
- What used to take months to determine clearance guidance now takes weeks
- Work execution was completed 50% faster, thanks to precise, data-backed targeting
Vegetation isn’t going to stop growing. But with a digital twin watching over it, utility firms don’t have to be caught off guard.
3. Optimized Grid Operations and Load Management
Balancing supply and demand in real-time is crucial for grid stability. Digital twins facilitate this by simulating various operational scenarios, allowing utilities to optimize energy distribution and manage loads effectively. By analyzing data from smart meters, sensors, and other grid components, potential bottlenecks can be identified and addressed proactively.
Here’s how it works in practice:
- Data from smart meters, IoT sensors, and control systems is funnelled into the digital twin.
- The platform then runs what-if scenarios:
- What happens if demand spikes in one region?
- What if a substation goes offline unexpectedly?
- How do EV charging surges affect residential loads?
These simulations allow utility firms to:
- Balance loads dynamically — shifting supply across regions based on actual demand
- Identify bottlenecks in the grid — before they lead to voltage drops or system trips
- Test responses to outages or disruptions — without touching the real infrastructure
One real-world application comes from Siemens, which uses digital twin technology to model substations across its power grid. By creating these virtual replicas, operators can:
- Detect voltage anomalies or reactive power imbalances quickly
- Simulate switching operations before pushing them live
- Reduce fault response time and improve grid reliability overall
This level of foresight turns grid management from a reactive firefighting role into a strategic, scenario-tested process.
When energy systems are stretched thin, especially with renewables feeding intermittent loads, a digital twin becomes less of a luxury and more of a grid operator’s control room essential.
4. Improved Emergency Response and Disaster Preparedness
When a storm hits, a wildfire spreads, or a substation goes offline unexpectedly, every second counts. Utility firms need more than just a damage report — they need situational awareness and clear action paths.
Digital twins give operators that clarity, before, during, and after an emergency.
Unlike traditional models that provide static views, digital twins offer live, geospatially aware environments that evolve in real time based on field inputs. This enables faster, better-coordinated responses across teams.
Here’s how digital twins strengthen emergency preparedness:
- Pre-event scenario planning
- Simulate storm surges, fire paths, or equipment failure to see how the grid will respond
- Identify weak links in the network (e.g. aging transformers, high-risk lines) and pre-position resources accordingly
- Real-time situational monitoring
- Integrate drone feeds, sensor alerts, and field crew updates directly into the twin
- Track which areas are inaccessible, where outages are expanding, and how restoration efforts are progressing
- Faster field deployment
- Dispatch crews with exact asset locations, hazard maps, and work orders tied to real-time conditions
- Reduce miscommunication and avoid wasted trips during chaotic situations
For example, during wildfires or hurricanes, digital twins can overlay evacuation zones, line outage maps, and grid stress indicators in one place — helping both operations teams and emergency planners align fast.
When things go wrong, digital twins don’t just help respond — they help prepare, so the fallout is minimised before it even begins.
5. Streamlined Regulatory Compliance and Reporting
For utility firms, compliance isn’t optional, it’s a constant demand. From safety inspections to environmental impact reports, regulators expect accurate documentation, on time, every time. Gathering that data manually is often time-consuming, error-prone, and disconnected across departments.
Digital twins simplify the entire compliance process by turning operational data into traceable, report-ready insights.
Here’s what that looks like in practice:
- Automated data capture
- Sensors feed real-time operational metrics (e.g., line loads, maintenance history, vegetation clearance) into the digital twin continuously
- No need to chase logs, cross-check spreadsheets, or manually input field data
- Built-in audit trails
- Every change to the system — from a voltage dip to a completed work order — is automatically timestamped and stored
- Auditors get clear records of what happened, when, and how the utility responded
- On-demand compliance reports
- Whether it’s for NERC reliability standards, wildfire mitigation plans, or energy usage disclosures, reports can be generated quickly using accurate, up-to-date data
- No scrambling before deadlines, no gaps in documentation
For utilities operating in highly regulated environments — especially those subject to increasing scrutiny over grid safety and climate risk — this level of operational transparency is a game-changer.
With a digital twin in place, compliance shifts from being a back-office burden to a built-in outcome of how the grid is managed every day.
Conclusion
Digital twin technology is revolutionizing the utility sector by enabling predictive maintenance, optimizing operations, enhancing emergency preparedness, and ensuring regulatory compliance. By adopting this technology, utility firms can improve reliability, reduce costs, and better serve their customers in an increasingly complex and demanding environment.
At SCS Tech, we specialize in delivering comprehensive digital transformation solutions tailored to the unique needs of utility companies. Our expertise in developing and implementing digital twin strategies ensures that your organization stays ahead of the curve, embracing innovation to achieve operational excellence.
Ready to transform your utility operations with proven digital utility solutions? Contact one of the leading digital transformation companies—SCS Tech—to explore how our tailored digital transformation strategy can help you predict and prevent failures.

