Cloud adoption is no longer an IT project — it’s a business imperative. Indian enterprises are migrating workloads, modernizing applications, and building cloud-native platforms to unlock agility, lower time-to-market, and support new AI and data initiatives. But while cloud adoption promises substantial value, it also introduces new operational, security, and cost-management challenges. This guide explains the benefits, lays out the common obstacles Indian enterprises face, and provides pragmatic best practices you can apply today.
Why Indian Enterprises are Adopting Cloud (Fast)
There are three business drivers behind the cloud push:
-
Speed & agility. Cloud lets teams provision infrastructure in minutes instead of weeks, accelerating development cycles and product launches.
-
Scalability & resilience. On-demand scaling helps enterprises handle peak loads and ensures business continuity without heavy upfront capital.
-
Data & AI readiness. Cloud platforms provide managed data, ML, and analytics services that make it far easier to build AI capabilities.
Most organizations are not choosing a single cloud — multi-cloud and hybrid strategies are now the norm as companies balance regulatory, performance, and cost concerns. Over 70% of enterprises are reported to be pursuing multi-cloud or hybrid strategies to keep flexibility and avoid vendor lock-in.
Tangible Benefits of Cloud Adoption
Cloud adoption delivers measurable business outcomes. The most common benefits Indian enterprises report include:
-
Faster innovation: Faster provisioning and managed services reduce friction for development and experimentation.
-
Cost flexibility: OPEX model reduces capital expenditure and converts fixed costs into variable costs tied to usage.
-
Operational efficiency: Managed services (databases, messaging, monitoring) reduce operational burden and free internal teams for higher-value work.
-
Improved reliability: Built-in redundancy, geo-replication, and managed backups increase uptime and data durability.
-
Better data insights: Cloud analytics and data lake services make it easier to centralize data and derive insights for decision-making.
These benefits are particularly important when organizations pursue AI initiatives: the cloud provides the GPU, storage, and orchestration layers needed for training and inference at scale (and for cost predictability if managed correctly). Gartner and industry analysts continue to emphasize the cloud as the foundation for modern AI deployments.
Top challenges Indian enterprises must anticipate
Cloud brings new failure modes that often surprise teams moving from on-prem environments. The most common pain points are:
-
Security & misconfiguration risks. Misconfigured cloud services (public buckets, overly permissive IAM roles, exposed APIs) are a major source of breaches and data exposure. Industry reports show misconfiguration and limited visibility remain top cloud security issues.
-
Cost overruns & poor governance. Many teams struggle with cost visibility and uncontrolled spend across accounts and projects — 94% of IT decision-makers in one survey reported trouble managing cloud costs. Unplanned AI/ML workloads only magnify this.
-
Complexity of hybrid/multi-cloud operations. Managing multiple providers, regions, and networking models increases operational complexity and skill requirements.
-
Skill gaps & cultural change. Shifting to cloud-native practices requires SRE/DevOps skills, FinOps maturity, and changes to procurement and architecture reviews.
-
Compliance & data residency. Industry regulations and data residency requirements drive architecture decisions (edge, region selection, on-prem fallbacks).
-
Vendor lock-in concerns. Overuse of provider-specific managed services can limit portability; enterprises need strategies that balance managed services with portability.
Understanding these threats up front helps you plan compensating controls and governance early — the organizations that treat cloud adoption as a cross-functional business program (not just an IT lift) achieve better outcomes. Recent industry reviews note that while cloud value is large, many transformations fall short without operational excellence and clear governance.
Practical Best Practices for Successful Cloud Adoption
Adopt the cloud intentionally — use a structured, phased approach that balances speed with governance.
1. Start with a business-first cloud strategy
Document business outcomes (time-to-market, cost targets, compliance needs) and map workloads to those outcomes. Not every workload should move at once; classify workloads as rehost, replatform, refactor, or retain and prioritize.
2. Build a Cloud Adoption Framework (CAF)
Use a proven framework (Azure CAF, AWS Well-Architected, Google Cloud Architecture Framework) to define landing zones, identity patterns, network topology, and security baselines. A CAF standardizes configurations and reduces misconfiguration risk.
3. Implement Zero Trust and cloud-native security controls
Adopt a Zero Trust mindset: least privilege IAM, encryption in transit and at rest, private networking for sensitive workloads, and strong secrets management. Automate security checks into CI/CD pipelines and perform continuous posture assessments.
4. Make cost governance a first-class capability (FinOps)
Create tagging and chargeback models, enforce budget alerts, and centralize cost reporting. Regularly review idle resources, leverage savings plans/reserved instances where appropriate, and run rightsizing recommendations. Treat FinOps as an ongoing operating discipline.
5. Automate everything (IaC & SRE principles)
Use Infrastructure as Code (Terraform/ARM/CloudFormation) to create reproducible environments and reduce configuration drift. Embed SRE practices: SLIs, SLOs, and runbooks so teams measure reliability and automate recovery.
6. Start small, prove value, then scale
Run pilot migrations for high-value but low-risk workloads. Use pilot outcomes to refine migration playbooks, security controls, and operational runbooks before large-scale migration.
7. Invest in people and change management
Upskill developers and operations staff on cloud patterns, DevOps, and FinOps. Create cross-functional pods that include security, compliance, finance, and infrastructure to accelerate decisions and reduce handoffs.
8. Secure the supply chain and third parties
Assess vendor security posture, require contractual security controls, and monitor third-party integrations. Supply-chain compromises often originate through trusted partners.
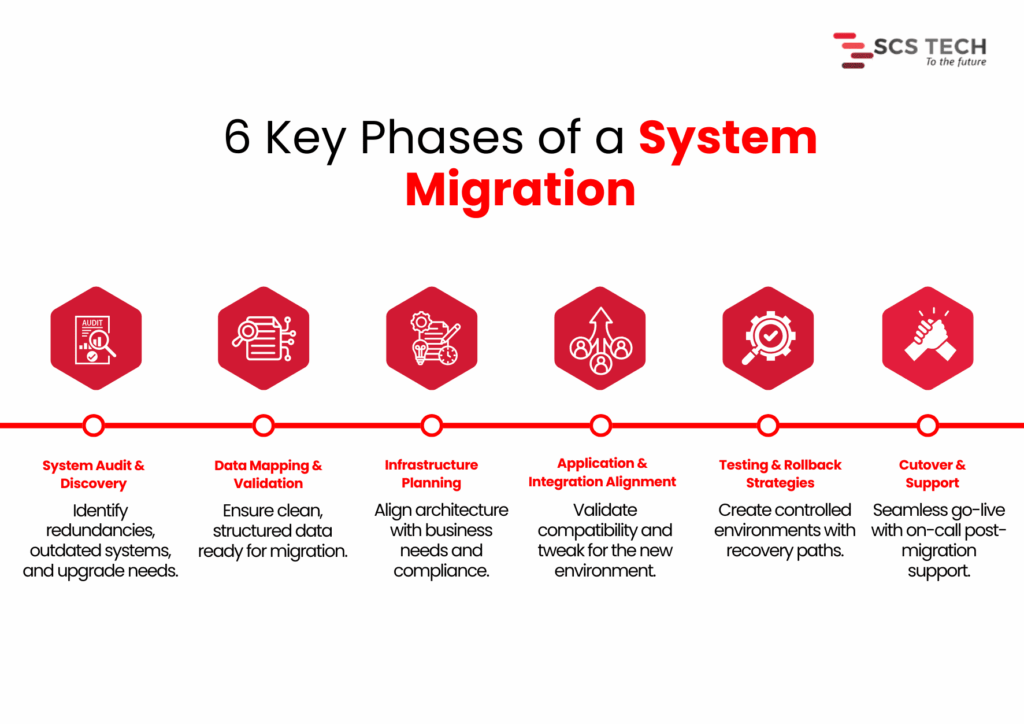
Quick Migration Checklist

Measuring success: KPIs that matter
Track metrics that align to business outcomes, for example:
-
Time to provision environment (minutes)
-
Mean time to recovery (MTTR) for production incidents
-
Cloud spend variance vs budget (%)
-
Percentage of workloads in approved landing zones (%)
-
Application availability/SLA compliance (%)
-
Deployment frequency and lead time for changes
Use these KPIs to continually improve tooling, governance, and the operating model.
Cloud Adoption is a Journey, Not a Switch
Cloud adoption can be transformational: faster product cycles, modern analytics, and a platform for AI innovation. But the upside requires disciplined governance, security by design, cost accountability, and a cultural shift toward automation and continuous improvement. Indian enterprises that combine a business-led strategy with proven cloud adoption frameworks and operational excellence will extract the most value — while avoiding the common pitfalls of misconfiguration, runaway costs, and weak governance.
For organizations navigating this journey, having the right technology partner can significantly reduce complexity and risk. SCS Tech India supports enterprises at every stage of cloud adoption—from strategy and secure architecture design to migration, optimization, and ongoing governance—ensuring cloud investments deliver measurable business value.