Both LiDAR and photogrammetry offer the accuracy of spatial data, yet that doesn’t simplify the choice. They fulfill the same function in GIS implementations but do so with drastically different technologies, expenses, and conditions in the field. LiDAR provides laser accuracy, as well as canopy penetration; photogrammetry provides high-resolution visuals, as well as velocity. However, selecting one without knowing where it will succeed or fail means the investment is wasted or the data is compromised.
Choosing the right technology also directly impacts the success of your GIS services, especially when projects are sensitive to terrain, cost, or delivery timelines.
This article compares them head-to-head across real-world factors: mapping accuracy, terrain adaptability, processing time, deployment requirements, and cost. You’ll see where one outperforms the other and where a hybrid approach might be smarter.
LiDAR vs Photogrammetry: Key Differences
LiDAR and photogrammetry are two of GIS’s most popular techniques for gathering spatial data. Both are intended to record real-world environments but do so in dramatically different manners.
LiDAR (Light Detection and Ranging) employs laser pulses to estimate distances between a sensor and targets on the terrain. These pulses bounce back towards the sensor to form accurate 3D point clouds. It is functional in many light environments and can even scan through vegetation to map the ground.
Photogrammetry, however, utilizes overlapping photographs taken from cameras, usually placed on drones or airplanes. These photos are then computer-processed to construct the shape and location of objects in 3D space. It is greatly dependent on favorable lighting and open visibility to produce good results.
Both methods are supportive of GIS mapping, although one might be more beneficial than the other based on project needs. Here’s where they vary in terms of principal differences:
- Accuracy in GIS Mapping
- Terrain Suitability & Environmental Conditions
- Data Processing & Workflow Integration
- Hardware & Field Deployment
- Cost Implications
Accuracy in GIS Mapping
When your GIS implementation is contingent upon accurate elevation and surface information, applications such as flood modeling, slope analysis, or infrastructure planning, the quality of your data collection means the project makes it or breaks it.
LiDAR delivers strong vertical accuracy thanks to laser pulse measurements. Typical airborne LiDAR surveys achieve vertical RMSE (Root Mean Square Error) between 5–15 cm, and in many cases under 10 cm, across various terrain types. Urban or infrastructure-focused LiDAR (like mobile mapping) can even get vertical RMSE down to around 1.5 cm.
Photogrammetry, on the other hand, provides less accurate vertical accuracy. Generally, most good-quality drone photogrammetry is able to produce around 10–50 cm RMSE in height, although horizontal accuracy is usually 1–3 cm. Tighter vertical accuracy is more difficult to achieve and requires more ground control points, improved image overlap, and good lighting, all require more money and time.
For instance, an infrastructure corridor that must be accurately elevated to plan drainage may be compromised by photogrammetry alone. A LiDAR survey would be sure to collect the small gradients required for good water flow or grading design, however.
- Use LiDAR when vertical accuracy is critical, for elevation modeling, flood risk areas, or engineering requirements.
- Use photogrammetry for horizontal mapping or visual base layers where small elevation errors are acceptable and the cost is a constraint.
These distinctions are particularly relevant when planning GIS in India, where both urban infrastructure and rural landscapes present diverse elevation and surface data challenges.
Terrain Suitability & Environmental Conditions
Choosing between LiDAR and photogrammetry often comes down to the terrain and environmental conditions where you’re collecting data. Each method responds differently based on vegetation, land type, and lighting.
LiDAR performs well in vegetated and complex situations. Its laser pulses penetrate the thick canopy and produce reliable ground models even with heavy cover. For instance, LiDAR has been found to be trustworthy where there are forest canopies of 30 meters, and it keeps its vertical accuracy within 10–15 cm as opposed to photogrammetry, which usually cannot trace the ground surface under heavy vegetation.
Photogrammetry excels in flat, open, and well-illuminated conditions. It relies on unobstructed lines of sight and substantial lighting. In open spaces such as fields or urban areas devoid of tree cover, it produces high-resolution images and good horizontal positioning, usually 1–3 cm horizontal accuracy, although vertical accuracy deteriorates to 10–20 cm in uneven terrain or light.
Environmental resilience also varies:
- Lighting and weather: LiDAR is largely unaffected by lighting conditions and can operate at night or under overcast skies. In contrast, photogrammetry requires daylight and consistent lighting to avoid shadows and glare affecting model quality.
- Terrain complexity: Rugged terrain featuring slopes, cliffs, or mixed surfaces can unduly impact photogrammetry, which relies on visual triangulation. LiDAR’s active sensing covers complex landforms more reliably.
“LiDAR is particularly strong in dense forest or hilly terrain, like cliffs or steep slopes”.
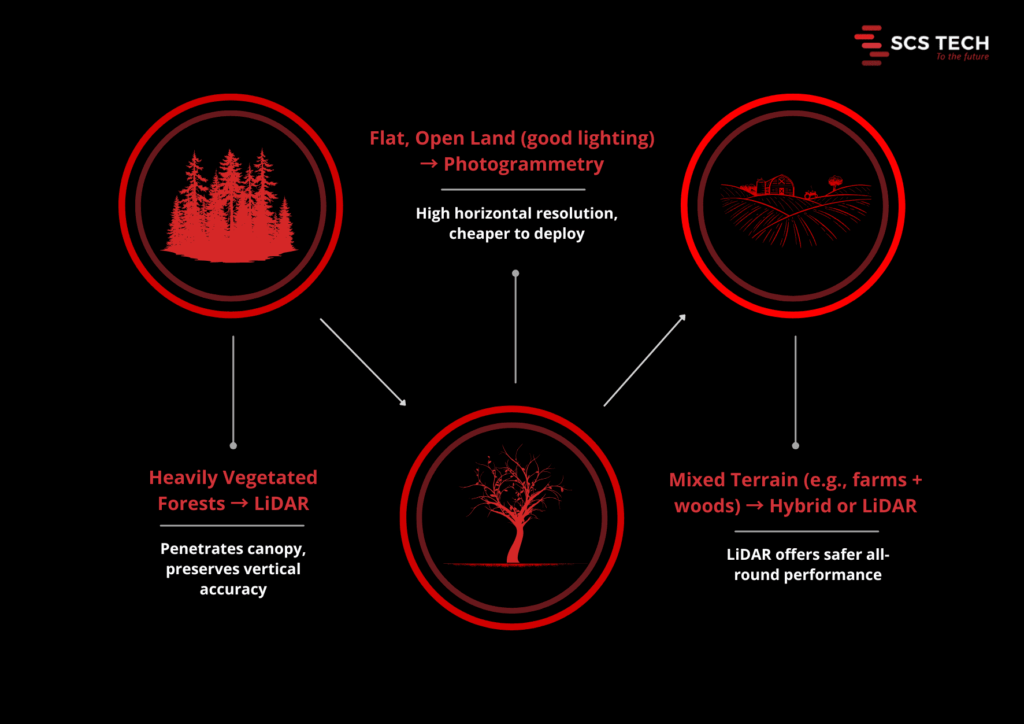
Choosing Based on Terrain
- Heavy vegetation/forests – LiDAR is the obvious choice for accurate ground modeling.
- Flat, open land with excellent lighting – Photogrammetry is cheap and reliable.
- Mixed terrain (e.g., farmland with woodland margins) – A hybrid strategy or LiDAR is the safer option.
In regions like the Western Ghats or Himalayan foothills, GIS services frequently rely on LiDAR to penetrate thick forest cover and ensure accurate ground elevation data.
Data Processing & Workflow Integration
LiDAR creates point clouds that require heavy processing. Raw LiDAR data can be hundreds of millions of points per flight. Processing includes noise filtering out, classifying ground vs non-ground returns, and developing surface models such as DEMs and DSMs.
This usually needs to be done using dedicated software such as LAStools or TerraScan and trained operators. High-volume projects may take weeks to days to process completely, particularly if classification is done manually. With current LiDAR processors that have AI-based classification, processing time can be minimized by up to 50% without a reduction in quality.
Photogrammetry pipelines revolve around merging overlapping images into 3D models. Tools such as Pix4D or Agisoft Metashape automatically align hundreds of images to create dense point clouds and meshes. Automation is an attractive benefit for companies offering GIS services, allowing them to scale operations without compromising data quality.
The processing stream is heavy, but very automated. However, image quality is a function of image resolution and overlap. A medium-sized survey might be processed within a few hours on an advanced workstation, compared to a few days with LiDAR. Yet for large sites, photogrammetry can involve more manual cleanup, particularly around shaded or homogeneous surfaces.
- Choose LiDAR when your team can handle heavy processing demands and needs fully classified ground surfaces for advanced GIS analysis.
- Choose photogrammetry if you value faster setup, quicker processing, and your project can tolerate some manual data cleanup or has strong GCP support.
Hardware & Field Deployment
Field deployment brings different demands. The right hardware ensures smooth and reliable data capture. Here’s how LiDAR and photogrammetry compare on that front.
LiDAR Deployment
LiDAR requires both high-capacity drones and specialized sensors. For example, the DJI Zenmuse L2, used with the Matrice 300 RTK or 350 RTK drones, weighs about 1.2 kg and delivers ±4 cm vertical accuracy, scanning up to 240k points per second and penetrating dense canopy effectively. Other sensors, like the Teledyne EchoOne, offer 1.5 cm vertical accuracy from around 120 m altitude on mid-size UAVs.
These LiDAR-capable drones often weigh over 6 kg without payloads (e.g., Matrice 350 RTK) and can fly for 30–55 minutes, depending on payload weight.
So, LiDAR deployment requires investment in heavier UAVs, larger batteries, and payload-ready platforms. Setup demands trained crews to calibrate IMUs, GNSS/RTK systems, and sensor mounts. Teams offering GIS consulting often help clients assess which hardware platform suits their project goals, especially when balancing drone specs with terrain complexity.
Photogrammetry Deployment
Photogrammetry favors lighter drones and high-resolution cameras. Systems like the DJI Matrice 300 equipped with a 45 MP Zenmuse P1 can achieve 3 cm horizontal and 5 cm vertical accuracy, and map 3 km² in one flight (~55 minutes).
Success with camera-based systems relies on:
- Mechanical shutters to avoid image distortion
- Proper overlaps (80–90%) and stable flight paths
- Ground control points (1 per 5–10 acres) using RTK GNSS for centimeter-level geo accuracy
Most medium-sized surveys run on 32–64 GB RAM workstations with qualified GPUs.
Deployment Comparison at a Glance
| Aspect | LiDAR | Photogrammetry |
| Drone requirements | ≥6 kg payload, long battery life | 3–6 kg, standard mapping drones |
| Sensor setup | Laser scanner, IMU/GNSS, calibration needed | High-resolution camera, mechanical shutter, GCPs/RTK |
| Flight time impact | Payload reduces endurance ~20–30% | Similar reduction; camera weight less critical |
| Crew expertise required | High—sensor alignment, real-time monitoring | Moderate — flight planning, image quality checks |
| Processing infrastructure | High-end PC, parallel LiDAR tools | 32–128 GB RAM, GPU-enabled for photogrammetry |
LiDAR demands stronger UAV platforms, complex sensor calibration, and heavier payloads, but delivers highly accurate ground models even under foliage.
Photogrammetry is more accessible, using standard mapping drones and high-resolution cameras. However, it requires careful flight planning, GCP setup, and capable processing hardware.
Cost Implications
LiDAR requires a greater initial investment. A full LiDAR system, which comprises a laser scanner, an IMU, a GNSS, and a compatible UAV aircraft, can range from $90,000 to $350,000. Advanced models such as the DJI Zenmuse L2, combined with a Matrice 300 or 350 RTK aircraft, are common in survey-grade undertakings.
If you’re not buying in bulk, LiDAR data collection services typically begin at about $300 an hour and go higher than $1,000 based on the type of terrain and resolution needed.
Photogrammetry tools are considerably more affordable. An example is a $2,000 to $20,000 high-resolution drone with a mechanical shutter camera. In most business applications, photogrammetry services are charged at $150-$500 per hour, which makes it a viable alternative for repeat or cost-conscious mapping projects.
In short, LiDAR costs more to deploy but may save time and manual effort downstream. Photogrammetry is cheaper upfront but demands more fieldwork and careful processing. Your choice depends on the long-term cost of error versus the up-front budget you’re working with.
A well-executed GIS consulting engagement often clarifies these trade-offs early, helping stakeholders avoid costly over-investment or underperformance.
Final Take: LiDAR vs Photogrammetry for GIS
A decision between LiDAR and photogrammetry isn’t so much about specs. It’s about understanding which one fits with your site conditions, data requirements, and the results your project relies on.
Both are strong suits. LiDAR provides you with improved results on uneven ground, heavy vegetation, and high-precision operations. Photogrammetry provides lean operation when you require rapid, broad sweeps in open spaces. But the true potential lies in combining them, with one complementing the other where it is needed.
If you’re unsure which direction to take, a focused GIS consulting session with SCSTech can save weeks of rework and ensure your spatial data acquisition is aligned with project outcomes. Whether you’re working on smart city development or agricultural mapping, selecting the right remote sensing method is crucial for scalable GIS projects in India.
We don’t just provide LiDAR or photogrammetry; our GIS services are tailored to deliver the right solution for your project’s scale and complexity.
Consult with SCSTech to get a clear, technical answer on what fits your project, before you invest more time or budget in the wrong direction.