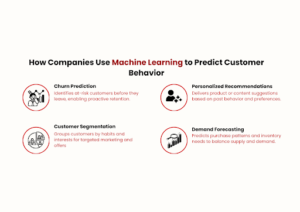
Digital transformation has evolved from a forward-looking strategy into a fundamental requirement for operational success. As India moves deeper into 2026, organizations across industries are recognizing that traditional digital transformation approaches are no longer enough. What truly accelerates transformation today is the integration of Artificial Intelligence (AI) and Machine Learning (ML) into core business systems.
Unlike earlier years, where AI was viewed as an advanced technology reserved for innovation labs, it is now embedded in everyday operational workflows. Whether it’s streamlining supply chains, automating customer interactions, predicting equipment failures, or enhancing cybersecurity, AI and ML are enabling organizations to move from reactive functioning to proactive, intelligent operations.
In this blog, we explore how AI and ML are reshaping digital transformation in 2026, what trends are driving adoption, and how enterprises in India can leverage these technologies to build a future-ready business.
AI & ML: The Foundation of Modern Digital Transformation
AI and ML have become the backbone of digital transformation because they allow organizations to process large amounts of data, identify patterns, automate decisions, and optimize workflows in real time. Companies are no longer implementing AI as an “optional enhancement” — instead, AI is becoming the central engine of digital operations.
At its core, AI-powered digital transformation enables companies to achieve what previously required human intervention, multiple tools, and considerable resources. Now, tasks that once took hours or days can be completed within minutes, and with far higher accuracy.
AI & ML empower enterprises to:
-
Improve decision-making through real-time insights
-
Understand customer behavior with greater precision
-
Optimize resources and reduce operational waste
-
Enhance productivity through intelligent automation
-
Strengthen cybersecurity using predictive intelligence
This shift toward AI-first strategies is defining the competitive landscape in 2026.
Key AI & ML Trends Driving Digital Transformation in 2026
AI capabilities are expanding rapidly, and these advancements are shaping how organizations modernize their digital ecosystems. The following trends are particularly influential this year.
a) Hyper-Automation as the New Operational Standard
Hyper-automation integrates AI, ML, and RPA to automate complex business processes end-to-end. Organizations are moving beyond basic automation to create fully intelligent workflows that require minimal manual oversight.
Many enterprises are using hyper-automation to streamline back-office operations, accelerate service delivery, and reduce human errors. For instance, financial services companies can now process loan applications, detect fraud, and verify customer documents with near-perfect accuracy in a fraction of the usual time.
Businesses rely on hyper-automation for:
-
Smart workflow routing
-
Automated document processing
-
Advanced customer onboarding
-
Predictive supply chain operations
-
Real-time process optimization
The efficiency gains are substantial, often reducing operational costs by 20–40%.
b) Predictive Analytics for Data-Driven Decision Making
Data is the most valuable asset of modern enterprises — but it becomes meaningful only when organizations can interpret it accurately. Predictive analytics enables businesses to forecast events, trends, and behaviors using historical and real-time data.
In 2026, predictive analytics will be used across multiple functions. Manufacturers rely on it to anticipate machine breakdowns before they occur. Retailers use it to forecast demand fluctuations. Financial institutions apply it to assess credit risks with greater accuracy.
Predictive analytics helps organizations:
-
Reduce downtime
-
Improve financial planning
-
Understand market movements
-
Personalize customer experiences
-
Prevent operational disruptions
Companies that adopt predictive analytics experience greater agility and competitiveness.
c) AI-Driven Cybersecurity and Threat Intelligence
As organizations expand digitally, cyber threats have grown more complex. With manual monitoring proving insufficient, AI-based cybersecurity solutions are becoming essential.
AI enhances security by continuously analyzing network patterns, identifying anomalies, and responding to threats instantly. This real-time protection helps organizations mitigate attacks before they escalate.
AI-powered cybersecurity enables:
-
Behavioral monitoring of users and systems
-
Automated detection of suspicious activity
-
Early identification of vulnerabilities
-
Prevention of data breaches
-
Continuous incident response
Industries such as BFSI, telecom, and government depend heavily on AI-driven cyber resilience.
d) Intelligent Cloud Platforms for Scalability and Efficiency
The cloud is no longer just a storage solution — it has become an intelligent operational platform. Cloud service providers now integrate AI into the core of their services to enhance scalability, security, and flexibility.
AI-driven cloud systems can predict demand, allocate resources automatically, and detect potential failures before they occur. This results in faster applications, reduced costs, and higher reliability.
Intelligent cloud technology supports digital transformation by enabling companies to innovate rapidly without heavy infrastructure investments.
e) Generative AI for Enterprise Productivity
Generative AI (GenAI) has revolutionized enterprise workflows. Beyond creating text or images, GenAI now assists in tasks such as documentation, coding, research, and training.
Instead of spending hours creating technical manuals, training modules, or product descriptions, employees can now generate accurate drafts within minutes and refine them as needed.
GenAI enhances productivity through:
-
Automated content generation
-
Rapid prototyping and simulations
-
Code generation and debugging
-
Data summarization and analysis
-
Knowledge management
Organizations using GenAI report productivity improvements of 35–60%.

How AI Is Transforming Key Industries in India
AI adoption varies across industries, but the impact is widespread and growing. Below are some sectors experiencing notable transformation.
Healthcare
AI is revolutionizing diagnostics, patient management, and clinical decision-making in India.
Hospitals use AI-enabled tools to analyze patient records, medical images, and vital signs, helping doctors make faster and more accurate diagnoses.
Additionally, predictive analytics helps healthcare providers anticipate patient needs and plan treatments more effectively. Automated hospital management systems further improve patient experience and reduce administrative workload.
Banking & Financial Services (BFSI)
The BFSI sector depends on AI for security, customer experience, and operational efficiency.
Banks now use AI-based systems to detect fraudulent transactions, assess creditworthiness, automate customer service, and enhance compliance.
With the rise of digital payments and online banking, AI enables financial institutions to maintain trust while delivering seamless customer experiences.
Manufacturing
Manufacturers in India are integrating AI into production lines, supply chain systems, and equipment monitoring.
AI-driven predictive maintenance significantly reduces downtime, while computer vision tools perform real-time quality checks to maintain consistency across products.
Digital twins — virtual replicas of physical systems — allow manufacturers to test processes and optimize performance before actual deployment.
Retail & E-Commerce
AI helps retail companies understand customer preferences, forecast demand, manage inventory, and optimize pricing strategies.
E-commerce platforms use AI-powered recommendation engines to deliver highly personalized shopping experiences, leading to higher conversion rates and increased customer loyalty.
Government & Smart Cities
Smart city initiatives across India use AI for traffic management, surveillance, GIS mapping, and incident response.
Government services are becoming more citizen-friendly by automating workflows such as applications, approvals, and public queries.
Benefits of AI & ML in Digital Transformation
AI brings measurable improvements across multiple aspects of business operations.
Key benefits include:
-
Faster and more accurate decision-making
-
Higher productivity through automation
-
Reduction in operational costs
-
Enhanced customer experiences
-
Stronger security and risk management
-
Increased agility and innovation
These advantages position AI-enabled enterprises for long-term success.
Challenges Enterprises Face While Adopting AI
Despite its potential, AI implementation comes with challenges.
Common barriers include:
-
Lack of AI strategy or roadmap
-
Poor data quality or fragmented data
-
Shortage of skilled AI professionals
-
High initial implementation costs
-
Integration issues with legacy systems
-
Concerns around security and ethics
Understanding these challenges helps organizations plan better and avoid costly mistakes.
How Enterprises Can Prepare for AI-Powered Transformation
Organizations must take a structured approach to benefit fully from AI.
Steps to build AI readiness:
-
Define a clear AI strategy aligned with business goals
-
Invest in strong data management and analytics systems
-
Adopt scalable cloud platforms to support AI workloads
-
Upskill internal teams in data science and automation technologies
-
Start small—test AI in pilot projects before enterprise-wide rollout
-
Partner with experienced digital transformation providers
A guided, phased approach minimizes risks and maximizes ROI.
Why Partner with SCS Tech India for AI-Led Digital Transformation?
SCS Tech India is committed to helping organizations leverage AI to its fullest potential. With expertise spanning digital transformation, AI/ML engineering, cybersecurity, cloud technology, and GIS solutions, the company delivers results-driven transformation strategies.
Organizations choose SCS Tech India because of:
-
Proven experience across enterprise sectors
-
Strong AI and ML development capabilities
-
Scalable and secure cloud and data solutions
-
Deep expertise in cybersecurity
-
Tailored transformation strategies for each client
-
A mature, outcome-focused implementation approach
Whether an enterprise is beginning its AI journey or scaling across departments, SCS Tech India provides end-to-end guidance and execution.
Wrapping Up!
AI and Machine Learning are redefining what digital transformation means in 2026. These technologies are enabling organizations to move faster, work smarter, and innovate continuously. Companies that invest in AI today will lead their industries tomorrow.
Digital transformation is no longer just about adopting new technology — it’s about building an intelligent, agile, and future-ready enterprise. With the right strategy and partners like SCS Tech India, businesses can unlock unprecedented levels of efficiency, resilience, and growth.