Every healthcare provider today relies on digital systems.
But too often, those systems don’t talk to each other in a way that keeps patient data safe. This isn’t just a technical oversight; it’s a risk that shows up in compliance audits, government penalties, and public breaches. In fact, most HIPAA violations aren’t caused by hackers, they stem from poor system integration, generic cybersecurity tools, or overlooked access logs.
And when those systems fail to catch a misstep, the aftercoming cost can be severe: it will be more than six-figure fines, federal audits, and long-term reputational damage.
That’s where custom cybersecurity solutions adds more tools to align security with the way your healthcare operations actually run. When security is designed around your clinical workflows, your APIs, and your data-sharing practices, it doesn’t just protect — it prevents.
In this article, we’ll unpack how integrated, custom-built cybersecurity helps healthcare organizations stay compliant, avoid HIPAA penalties, and defend what matters most: patient trust.
Understanding HIPAA Compliance and Its Real-World Challenges
HIPAA isn’t just a legal framework, it’s a daily operational burden for any healthcare provider managing electronic Protected Health Information (ePHI). While the regulation is clear about what must be protected, it’s far less clear about how to do it, especially in systems that weren’t built with healthcare in mind.
Here’s what makes HIPAA compliance difficult in practice:
- Ambiguity in Implementation: The security rule requires “reasonable and appropriate safeguards,” but doesn’t define a universal standard. That leaves providers guessing whether their security setup actually meets expectations.
- Fragmented IT Systems: Most healthcare environments run on a mix of EHR platforms, custom apps, third-party billing systems, and legacy hardware. Stitching all of this together while maintaining consistent data protection is a constant challenge.
- Hidden Access Points: APIs, internal dashboards, and remote access tools often go unsecured or unaudited. These backdoors are commonly exploited during breaches, not because they’re poorly built, but because they’re not properly configured or monitored.
- Audit Trail Blind Spots: HIPAA requires full auditability of ePHI, but without custom configurations, many logging systems fail to track who accessed what, when, and why.
Even good IT teams struggle here, not because they’re negligent, but because most off-the-shelf cybersecurity solutions aren’t designed to speak HIPAA natively. That’s what puts your organization at risk: doing what seems secure, but still falling short of what’s required.
That’s where custom cybersecurity solutions fill the gap, not by adding complexity, but by aligning every protection with real HIPAA demands.
How Custom Cybersecurity Adapts to the Realities of Healthcare Environments
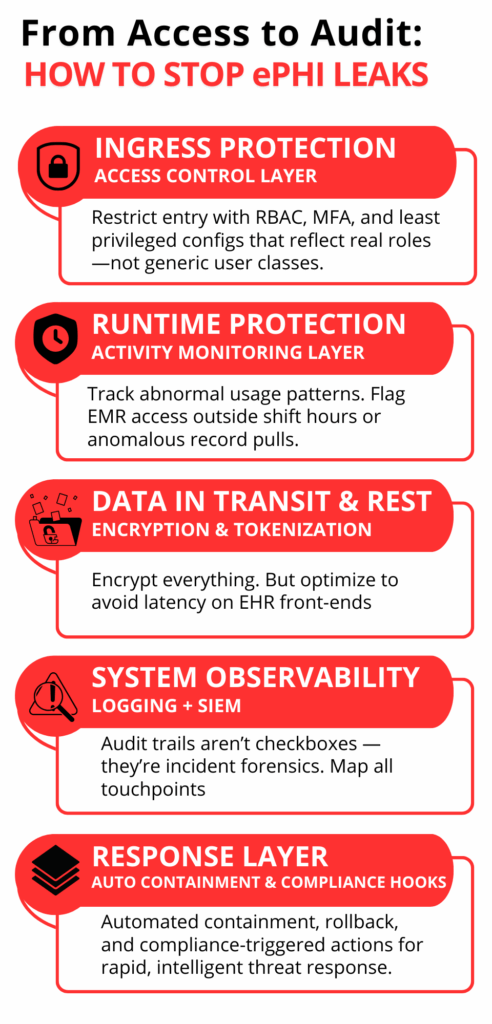
Custom cybersecurity tailors every layer of your digital defense to match your exact workflows, compliance requirements, and system vulnerabilities.
Here’s how that plays out in real healthcare environments:
-
Role-Based Access, Not Just Passwords
In many healthcare systems, user access is still shockingly broad — a receptionist might see billing details, a technician could open clinical histories. Not out of malice, just because default systems weren’t built with healthcare’s sensitivity in mind.
That’s where custom role-based access control (RBAC) becomes essential. It doesn’t just manage who logs in — it enforces what they see, tied directly to their role, task, and compliance scope.
For instance, under HIPAA’s “minimum necessary” rule, a front desk employee should only view appointment logs — not lab reports. A pharmacist needs medication orders, not patient billing history.
And this isn’t just good practice — it’s damage control.
According to Verizon’s Data Breach Investigations Report, over 29% of breaches stem from internal actors, often unintentionally. Custom RBAC shrinks that risk by removing exposure at the root: too much access, too easily given.
Even better? It simplifies audits. When regulators ask, “Who accessed what, and why?” — your access map answers for you.
-
Custom Alert Triggers for Suspicious Activity
Most off-the-shelf cybersecurity tools flood your system with alerts — dozens or even hundreds a day. But here’s the catch: when everything is an emergency, nothing gets attention. And that’s exactly how threats slip through.
Custom alert systems work differently. They’re not based on generic templates — they’re trained to recognize how your actual environment behaves.
Say an EMR account is accessed from an unrecognized device at 3:12 a.m. — that’s flagged. A nurse’s login is used to export 40 patient records in under 30 seconds? That’s blocked. The system isn’t guessing — it’s calibrated to your policies, your team, and your workflow rhythm.
-
Encryption That Works with Your Workflow
HIPAA requires encryption, but many providers skip it because it slows down their tools. A custom setup integrates end-to-end encryption that doesn’t disrupt EHR speed or file transfer performance. That means patient files stay secure, without disrupting the care timeline.
-
Logging That Doesn’t Leave Gaps
Security failures often escalate due to one simple issue: the absence of complete, actionable logging. When logs are incomplete, fragmented, or siloed across systems, identifying the source of a breach becomes nearly impossible. Incident response slows down. Compliance reporting fails. Liability increases.
A custom logging framework eliminates this risk. It captures and correlates activity across all touchpoints — not just within core systems, but also legacy infrastructure and third-party integrations. This includes:
- Access attempts (both successful and failed)
- File movements and transfers
- Configuration changes across privileged accounts
- Vendor interactions that occur outside standard EHR pathways
The HIMSS survey underscores that inadequate monitoring poses significant risks, including data breaches, highlighting the necessity for robust monitoring strategies.
Custom logging is designed to meet the audit demands of regulatory agencies while strengthening internal risk postures. It ensures that no security event goes undocumented, and no question goes unanswered during post-incident reviews.
The Real Cost of HIPAA Violations — and How Custom Security Avoids Them
HIPAA violations don’t just mean a slap on the wrist. They come with steep financial penalties, brand damage, and in some cases, criminal liability. And most of them? They’re preventable with better-fit security.
Breakdown of Penalties:
- Tier 1 (Unaware, could not have avoided): up to $50,000 per violation
- Tier 4 (Willful neglect, not corrected): up to $1.9 million annually
- Fines are per violation — not per incident. One breach can trigger dozens or hundreds of violations.
But penalties are just the surface:
- Investigation costs: Security audits, data recovery, legal reviews
- Downtime: Systems may be partially or fully offline during containment
- Reputation loss: Patients lose trust. Referrals drop. Insurance partners get hesitant.
- Long-term compliance monitoring: Some organizations are placed under corrective action plans for years
Where Custom Security Makes the Difference:
Most breaches stem from misconfigured tools, over-permissive access, or lack of monitoring, all of which can be solved with custom security. Here’s how:
- Precision-built access control prevents unnecessary exposure, no one gets access they don’t need.
- Real-time monitoring systems catch and block suspicious behavior before it turns into an incident.
- Automated compliance logging makes audits faster and proves you took the right steps.
In short: custom security shifts you from reactive to proactive, and that makes HIPAA penalties exponentially less likely.
What Healthcare Providers Should Look for in a Custom Cybersecurity Partner
Off-the-shelf security tools often come with generic settings and limited healthcare expertise. That’s not enough when patient data is on the line, or when HIPAA enforcement is involved. Choosing the right partner for custom cybersecurity solution isn’t just a technical decision; it’s a business-critical one.
What to prioritize:
- Healthcare domain knowledge: Vendors should understand not just firewalls and encryption, but how healthcare workflows function, where PHI flows, and what technical blind spots tend to go unnoticed.
- Experience with HIPAA audits: Look for providers who’ve helped other clients pass audits or recover from investigations — not just talk compliance, but prove it.
- Custom architecture, not pre-built packages: Your EHR systems, patient portals, and internal communication tools are unique. Your security setup should mirror your actual tech environment, not force it into generic molds.
- Threat response and simulation capabilities: Good partners don’t just build protections — they help you test, refine, and drill your incident response plan. Because theory isn’t enough when systems are under attack.
- Built-in scalability: As your organization grows — new clinics, more providers, expanded services — your security architecture should scale with you, not become a roadblock.
Final Note
Cybersecurity in healthcare isn’t just about stopping threats, it’s about protecting compliance, patient trust, and uninterrupted care delivery. When HIPAA penalties can hit millions and breaches erode years of reputation, off-the-shelf solutions aren’t enough. Custom cybersecurity solutions allow your organization to build defense systems that align with how you actually operate, not a one-size-fits-all mold.
At SCS Tech, we specialize in custom security frameworks tailored to the unique workflows of healthcare providers. From HIPAA-focused assessments to system-hardening and real-time monitoring, we help you build a safer, more compliant digital environment.
FAQs
1. Isn’t standard HIPAA compliance software enough to prevent penalties?
Standard tools may cover the basics, but they often miss context-specific risks tied to your unique workflows. Custom cybersecurity maps directly to how your organization handles data, closing gaps generic tools overlook.
2. What’s the difference between generic and custom cybersecurity for HIPAA?
Generic solutions are broad and reactive. Custom cybersecurity is tailored, proactive, and built around your specific infrastructure, user behavior, and risk landscape — giving you tighter control over compliance and threat response.
3. How does custom security help with HIPAA audits?
It allows you to demonstrate not just compliance, but due diligence. Custom controls create detailed logs, clear risk management protocols, and faster access to proof of safeguards during an audit.